3D-Aware Indoor Scene Synthesis with Depth Priors
ECCV 2022 (Oral)
1HKUST
2ByteDance Inc.

Figure: Left: High-fidelity images with the corresponding depths generated by DepthGAN.
Right: The 3D reconstruction results.



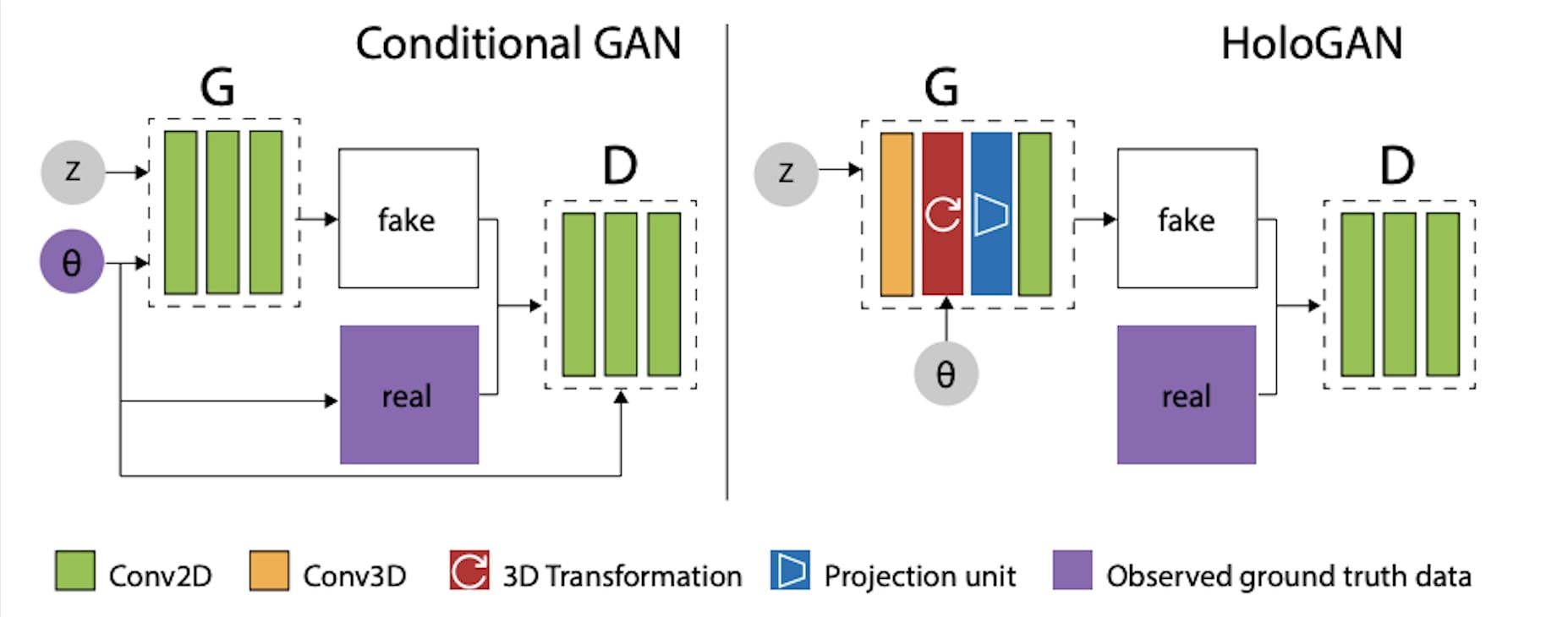
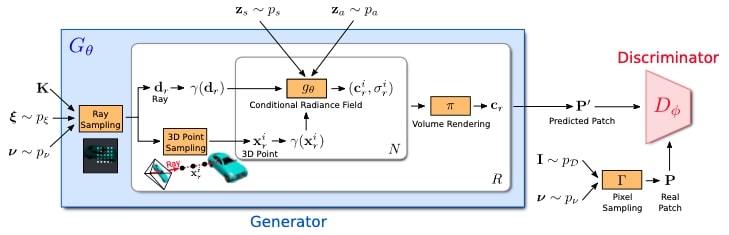
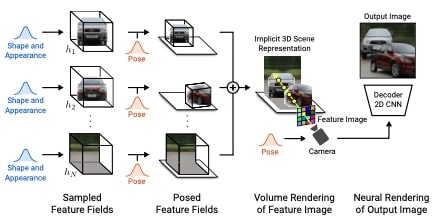
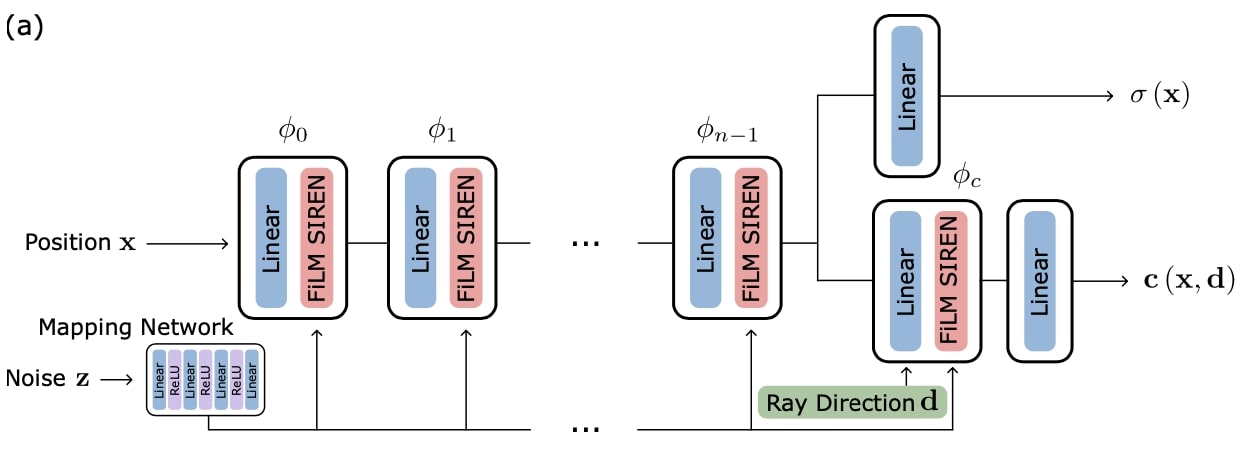
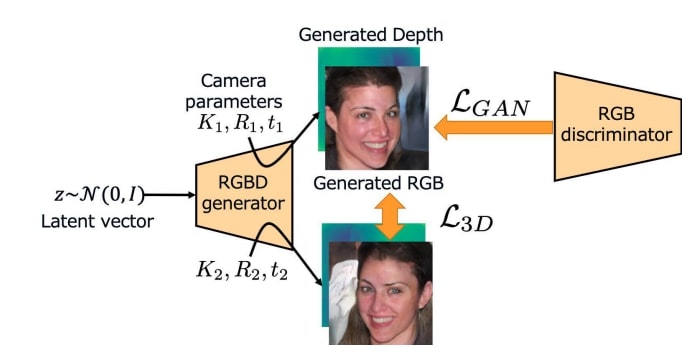
Comment: Proposes voxelized and implicit 3D representations and then render it to 2D image space with a reshape operation.